Determining the file at a specific VMDK offset again
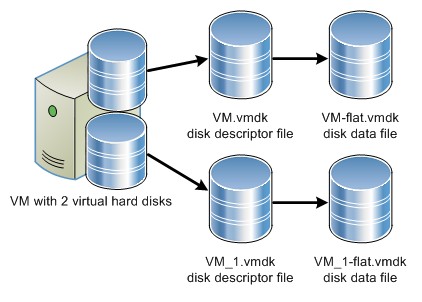
Not long after the previous post, I got yet another error, this time on an NTFS partition. This required a slightly different sequence of steps, so thought I’d document those for the next time this happens.
First I moved the dodgy virtual machine (/var/vmware/bnedev01/*) to a separate location on the hypervisor’s filesystem (/var/vmware/x/bnedev01-corrupt/*) , which will update the directory entries but keep the files in the same place, so the bad sectors on the hypervisor still affect the same files as before the move, relatively speaking. I then made a new copy of the virtual machine (back into /var/vmware/bnedev01/*), using dd to copy the vmdk extent that contained the bad sector on the hypervisor.
knoxg@bnehyp03:/var/vmware$ sudo mv bnedev01 x/bnedev01-corrupt [sudo] password for knoxg: ******** knoxg@bnehyp03:/var/vmware$ sudo cp -rp x/bnedev01-corrupt bnedev01 cp: reading `x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error knoxg@bnehyp03:/var/vmware$ cd bnedev01 knoxg@bnehyp03:/var/vmware/bnedev01$ sudo dd if=../x/bnedev01-corrupt/bnedev01-s003.vmdk of=./bnedev01-s003.vmdk bs=512 conv=noerror,sync dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+0 records in 2317784+0 records out 1186705408 bytes (1.2 GB) copied, 92.0692 s, 12.9 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+1 records in 2317785+0 records out 1186705920 bytes (1.2 GB) copied, 130.989 s, 9.1 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+2 records in 2317786+0 records out 1186706432 bytes (1.2 GB) copied, 167.489 s, 7.1 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+3 records in 2317787+0 records out 1186706944 bytes (1.2 GB) copied, 200.599 s, 5.9 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+4 records in 2317788+0 records out 1186707456 bytes (1.2 GB) copied, 227.789 s, 5.2 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+5 records in 2317789+0 records out 1186707968 bytes (1.2 GB) copied, 249.079 s, 4.8 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+6 records in 2317790+0 records out 1186708480 bytes (1.2 GB) copied, 272.069 s, 4.4 MB/s dd: reading `../x/bnedev01-corrupt/bnedev01-s003.vmdk': Input/output error 2317784+7 records in 2317791+0 records out 1186708992 bytes (1.2 GB) copied, 298.319 s, 4.0 MB/s 4190712+8 records in 4190720+0 records out 2145648640 bytes (2.1 GB) copied, 396.208 s, 5.4 MB/s
So pretty much the same thing as bnedev03 in the previous post, except the bad dd records/blocks are in bnedev01-s003.vmdk, and contained in the range 2317784 to 2317790.
To get the files corresponding to these blocks, I need to get the partition table on the disk, and run ntfsinfo over the C: partition. Notice that for this machine I’m running these commands outside the virtual machine, rather than inside as was the case for bnedev03.
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo mkdir /mnt/bnedev01-disk0
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo vmware-mount -f bnedev01.vmdk /mnt/bnedev01-disk0
Failed to open disk: The specified virtual disk needs repair (60129558150)
Failed to mount disk 'bnedev01.vmdk': Cannot open the virtual disk
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo vmware-vdiskmanager -R bnedev01.vmdk
The virtual disk, 'bnedev01.vmdk', was corrupted and has been successfully repaired.
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo vmware-mount -f bnedev01.vmdk /mnt/bnedev01-disk0
knoxg@bnehyp03:/var/vmware/bnedev01$ fdisk -l /mnt/bnedev01-disk0/flat
You must set cylinders.
You can do this from the extra functions menu.
Disk /mnt/bnedev01-disk0/flat: 0 MB, 0 bytes
255 heads, 63 sectors/track, 0 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x9fdd9fdd
Device Boot Start End Blocks Id System
/mnt/bnedev01-disk0/flat1 * 1 3917 31457248+ 7 HPFS/NTFS
Partition 1 has different physical/logical endings:
phys=(1023, 254, 63) logical=(3916, 63, 51)
Now I’ve got the partition table, I can setup a loopback device for the first partition, and check that it is recognised as an NTFS partition.
The loopback device /dev/loop0 is setup at offset 32256 into /mnt/bnedev01-disk0/flat; which is the starting sector (63) * number of bytes per sector (512), as described here.
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo losetup -f /dev/loop0 knoxg@bnehyp03:/var/vmware/bnedev01$ sudo losetup -o 32256 /dev/loop0 /mnt/bnedev01-disk0/flat knoxg@bnehyp03:/var/vmware/bnedev01$ sudo ntfsinfo -m /dev/loop0 Volume Information Name of device: /dev/loop0 Device state: 11 Volume Name: Volume State: 1 Volume Version: 3.1 Sector Size: 512 Cluster Size: 4096 Volume Size in Clusters: 7864311 MFT Information MFT Record Size: 1024 MFT Zone Multiplier: 1 MFT Data Position: 24 MFT Zone Start: 786432 MFT Zone End: 1769470 MFT Zone Position: 786432 Current Position in First Data Zone: 1769470 Current Position in Second Data Zone: 0 LCN of Data Attribute for FILE_MFT: 786432 FILE_MFTMirr Size: 4 LCN of Data Attribute for File_MFTMirr: 2095474 Size of Attribute Definition Table: 2560 FILE_Bitmap Information FILE_Bitmap MFT Record Number: 6 State of FILE_Bitmap Inode: 0 Length of Attribute List: 0 Attribute List: (null) Number of Attached Extent Inodes: 0 FILE_Bitmap Data Attribute Information Decompressed Runlist: not done yet Base Inode: 6 Attribute Types: not done yet Attribute Name Length: 0 Attribute State: 3 Attribute Allocated Size: 983040 Attribute Data Size: 983040 Attribute Initialized Size: 983040 Attribute Compressed Size: 0 Compression Block Size: 0 Compression Block Size Bits: 0 Compression Block Clusters: 0
So. To get the ntfs cluster number of the byte offset within the partition, we do similar steps as before:
- dd blocks 2317784 to 2317790
- = byte offset within
bnedev01-s003.vmdkof (2317784 * 512) to (2317790 * 512 + 511) - = byte offset within
bnedev01-s003.vmdkof 1186705408 to 1186708991 - = vmdk offset bytes (1186705408 + 2 * 4192256 * 512) to 1186708991 + 2 * 4192256 * 512)
(+ size of thebnedev01-s001.vmdkandbnedev01-s002.vmdkvmdk extents) - = vmdk offset bytes (1186705408 + 4292870144) to 1186708991 + 4292870144)
- = vmdk offset bytes 5479575552 to 5479579135
- = partition offset bytes (5479575552 – 32256) to (5479579135 – 32256)
- = partition offset bytes 5479543296 to 5479546879
- = ntfs clusters (5479543296 / 4096) to (5479546879 / 4096)
(since 4096 is the ‘Cluster Size’ in the output ofntfsinfoabove) - = ntfs clusters 1337779 to 1337779
And to get the file at cluster 1337779:
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo ntfscluster --cluster 1337779 /dev/loop0 2>/dev/null Searching for cluster 1337779 Inode 50224 /Documents and Settings/knoxg/Local Settings/Temp/wz345c/eclipse/plugins/org.apache.velocity_1.5.0.v200905192330.jar/$DATA
So again, not a terribly important file; rather than restoring this file from backup, I might as well just clear out the /Documents and Settings/knoxg/Local Settings/Temp folder.
To unmount the partition and the disk, you need to run something similar to:
knoxg@bnehyp03:/var/vmware/bnedev01$ sudo losetup -d /dev/loop0 knoxg@bnehyp03:/var/vmware/bnedev01$ sudo vmware-mount -k /var/vmware/bnedev01/bnedev01.vmdk
Followup
Once I booted back into the VM, I verified the disk layout under Start → Settings → Control Panel → Administrative Tools → Computer Management, from which you can bring up the Disk Management MMC snap-in by selecting it from the tree on the left hand side:
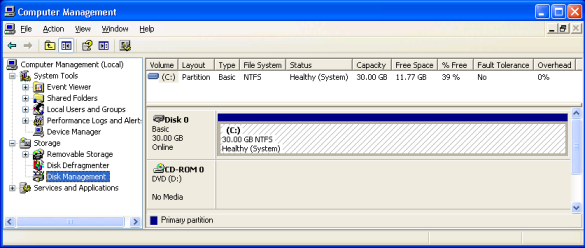
which agreed with the fdisk output above, and for good measure, I ran a chkdsk at a cmd prompt:
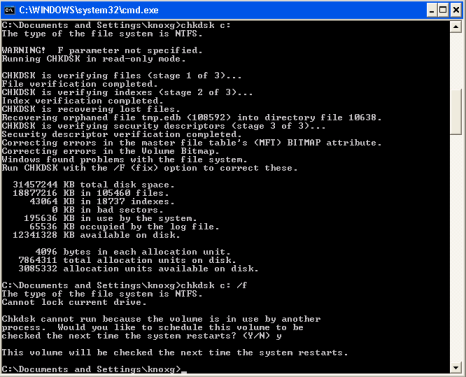
which then fixed up a few errors during the next startup:
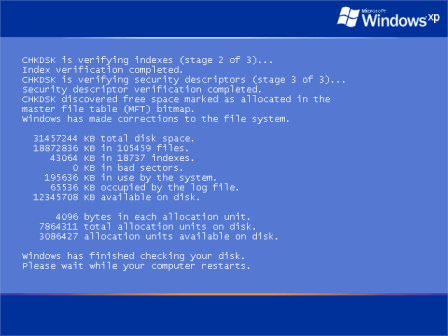
So there you have it. Go in peace, and it’s a Sunday so get to church you heathen scum.
Just a footnote on my method for ‘commenting out’ files/folders that I still want to retain for a while. I’ll normally put these under an ‘x‘ folder (or prefix ‘x-‘ to the filename), since it (a) usually drops it to the bottom of an alphabetic listing of the directory, and (b) reminds me vaguely of this Monty Python sketch).
If the file is a distribution file which I am then modifying, I usually append .orig to the old file instead.
If I need to change the extension because it will otherwise be picked up by an application server (via automatic application deployment) then I’ll append something like .nodeploy to the filename (so some-webapp.war becomes some-webapp.war.nodeploy)
If I need to change the extension because it will otherwise be picked up by something like javac *.java, then I’ll append something like .nocompile to it (so someClass.java becomes someClass.java.nocompile).